Managing OpenStack Virtual Machines to improve user experience, avoid capacity constraints and maximise hardware performance.
Managing OpenStack Virtual Machines to improve user experience, avoid capacity constraints and maximise hardware performance.
March 2019
OpenStack at Man Alpha Technology
About two years ago, we started migrating all our dev and research workloads to our OpenStack cluster.
We build and manage our virtual machines in OpenStack using a variety of Open Source software, such as Packer, Terraform, and Ansible. Typical workloads in the cluster include Linux VDIs, Slurm and Spark compute nodes, Jenkins build nodes, general dev machines, and various little VMs that handle small services such as HTTP and FTP servers. The VMs will range in size from about 2Gb of RAM and 1 CPU, all the way up to 256Gb of RAM and 24 CPUs.
Through instrumentation (using Prometheus), we know that our workloads are typically peaky - i.e. they need a lot of RAM and CPU for a while, but then the requirements quieten down until we have the next peak. With this in mind, we overprovision quite aggressively, as this allows us to run larger loads than what our systems would traditionally allow, saving both capital and operational expenses.
For our workloads, CPU overprovisioning basically doesn’t matter, but RAM isn’t elastic in the same way that CPU is - when it’s allocated, it’s allocated. However, we employ two strategies to eke out extra usable memory:
- Kernel Samepage Merging, which allows the hypervisor to deduplicate identical memory pages within the guest VMs (This can be thought of as ‘dedup for RAM’).
- Memory ballooning to manage the memory on our hypervisors and VMs. This link describes how memory ballooning works in VMWare, and the concept is similar in OpenStack.
Whilst our OpenStack cluster worked well, VMs with different usage profiles did not get distributed as evenly as we’d hoped: some nodes ran hotter than others, to the point that we’d run out of memory and a random VM would be killed by the OOM killer.
VM to hypervisor balancing
OpenStack will not re-balance itself automatically, and manual rebalancing is a repetitive and tedious task ripe for automation. We scoured the Internet for open source solutions, and found two potentially useful projects:
- Masakari is an official OpenStack project. It attempts to create highly available services by restarting VMs that have failed.
- Neat is a dynamic VM consolidation tool, using live migration. It aims to bin pack VMs onto as few hypervisors as possible, so that the idle hypervisors can be turned off to save energy.
Out of the two projects we found, Neat offered the most potential to solve our problem, but unfortunately it requires extra infrastructure to be in place (for example, it requires load monitoring agents to be running on the hypervisors, a database to store results, etc), and its stated goal is to consolidate everything onto as few hypervisors as possible. We actually want to achieve the opposite, so that our interactive workloads (people using the system) are as shielded from load as possible.
Introducing our Load Leveller
As we could not find anything suitable to solve our problem, we decided to roll our own! The key requirements for us were:
- Require as little extra infrastructure as possible. We do not want to have to run extra agents, or increase our dependencies on external databases and systems
- Make rational choices of what VM to move and where to move it
- Low maintenance.
We call our balancer the “Load Leveller”, and we believe it fulfils every requirement we had.
The Load Leveller plugs into our Prometheus installation to get up-to-date load / memory utilization for the hypervisors, and it then speaks to the OpenStack API to live-migrate VMs around.
The strategy the Leveller uses is:
- Find CPU and memory load metrics for the hypervisors from Prometheus
- Calculate a synthetic load score using CPU and Memory utilization
- Decide which hypervisor is the most loaded
- Decide which VM to move from the most loaded hypervisor, and also which hypervisor to move it to (bearing in mind that it must fit, be in the right availability zone, and have a compatible CPU spec)
- Live migrate (zero downtime) the selected VM to the selected hypervisor
- Repeat
Deciding which hypervisor to move a VM to sounds trivial, but in practice a VM cannot be live-migrated to e.g. a hypervisor with different CPUs, or where it doesn’t fit due to RAM requirements, and quite a bit of work had to be done to select a correct hypervisor.
Does the Load Leveller work?
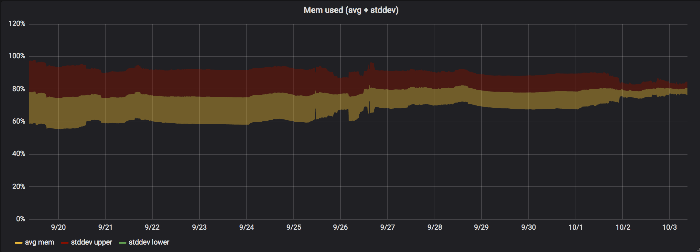
Here’s a graph showing the average memory utilization on a hypervisor before and after running the Leveller. The bands are one standard deviation wide. We turned the Leveller on towards the right of the graph, and you can clearly see how the standard deviation narrows down to produce a much smaller overall band (i.e. there is less variation in memory usage).
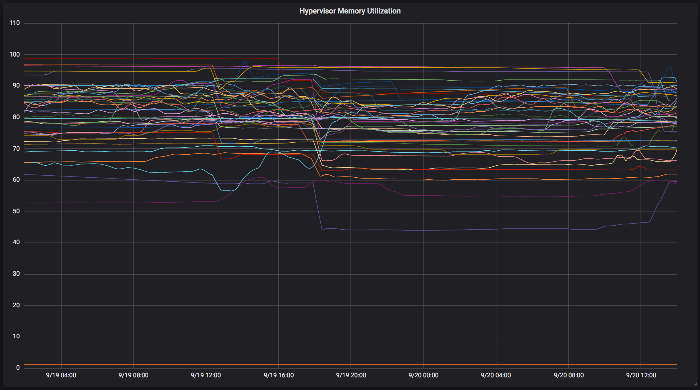
The following two graphs show this in more detail. The first one shows typical memory utilization on our hypervisors before automatic balancing, using the default OpenStack placement algorithm. Some are very close to 100% utilized, whilst others are less than 60% used.
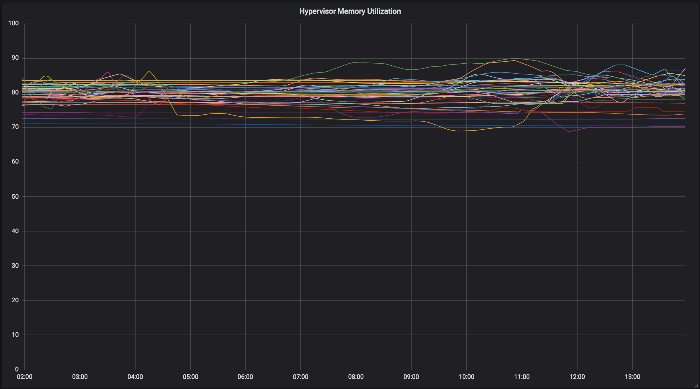
The second graph shows memory utilization after running the Leveller for a period of time. You can see that the spread has tightened in the detail view as well.
How do I get/use Load Leveller?
The Leveller is open source, and it can be downloaded from our Github repo
The requirements are:
- An OpenStack setup with a user that can see/migrate any VMs in any project (usually admin)
- A prometheus setup that exposes memory and CPU metrics in some form
The actual Prometheus queries can be configured using normal Prometheus expressions, and as long as they produce a scaled value for memory/CPU utilization, they should work as inputs.
Installation/configuration information can be found at the Github repo linked above.
Final thoughts
Our Load Leveller seems to be working well for us. Even though the load balancing algorithm it uses is quite simple, it has stopped the periodic OOM issues we had with hypervisors.
Our OpenStack setup has several versions of CPUs with differing capabilities, and a VM cannot live migrate between CPUs unless they share the exact same set of capabilities, so we had to write filters to find the set of potential machines to move to, which complicated the code somewhat. We could disable certain CPU flags to be able to live-migrate between all hypervisors, but some of our work loads can take advantage of the AVX-512 CPU instructions, and we don’t want to disable this feature just to enable live-migration.
OpenStack natively supports live migration of a VM to “any other host” as well, i.e. a mode where it is not necessary to specify the destination. We tried this in the original version of the Leveller, but it turns out that the automatic selection of nodes is unpredictable (or at least not tuned in the way we want). Quite often OpenStack would opt to move a VM from a hypervisor low on memory to another hypervisor that was equally tight on memory (causing the destination HV to start swapping). Perhaps it’d be possible to improve the automatic selection mechanism, as OpenStack should have all required knowledge of where to place VMs, but nevertheless the Load Leveller solves our own VM scheduling problem elegantly, without causing any extra work for the Linux team.
You are now exiting our website
Please be aware that you are now exiting the Man Group website. Links to our social media pages are provided only as a reference and courtesy to our users. Man Group has no control over such pages, does not recommend or endorse any opinions or non-Man Group related information or content of such sites and makes no warranties as to their content. Man Group assumes no liability for non Man Group related information contained in social media pages. Please note that the social media sites may have different terms of use, privacy and/or security policy from Man Group.